
In March 2024, a startup called Cognition Labs released a short demo video showing an AI system called Devin receiving a software task, breaking it into steps, writing code, running tests, hitting errors, researching solutions on its own, and producing a working result without a human touching the keyboard.
The company described it as the world’s first AI software engineer.
It was also referred to as an autonomous software engineering system capable of handling complex engineering workflows end-to-end, from planning to execution to iteration, with minimal human guidance.
The demo generated immediate attention across the developer community, drawing strong reactions from engineers, researchers, and industry observers alike, with some highlighting its potential and others questioning its claims and limitations.
Although this was about two years ago, the questions it surfaced have not gone away. If anything, they’ve become more relevant:
- What exactly does it mean for a software engineer to be autonomous?
- How does it differ from the AI coding tools already in widespread use?
- What can these systems do in production environments, and where do they still fall short?
And perhaps most importantly, what does this mean for the teams responsible for building and maintaining software today?
These questions deserve a grounded answer, and that is what this article aims to provide.
“AI-Assisted” vs “AI Autonomous”
Autonomous software engineering is one of those phrases that gets applied to a wide range of things, from smarter autocomplete to fully independent agents, so it helps to be specific about where the meaningful line is.
AI-assisted coding tools like GitHub Copilot are a good example of the former model. They are designed to assist while you work, by analyzing the code you are writing, predicting what should come next, catching obvious errors, and generating boilerplate.
A copilot assists; it does not act on its own. The developer still owns every decision: what to build, how to break it down, when to accept a suggestion, and what to do next. The AI contributes within the frame the human sets and has no concept of a goal independent of the prompt in front of it.
An autonomous software engineer works differently. You give it a goal rather than a prompt. From there, it plans the work, decomposes it into subtasks, writes and edits code, runs tests, reads error logs, researches solutions when it gets stuck, and iterates until it reaches a stopping point, all without step-by-step human instruction.
The underlying technical approach, what practitioners call an agentic loop, is what makes this possible. The model decomposes a goal into a plan, selects a tool to execute the first step, observes the result, decides what to do next, and continues iterating.
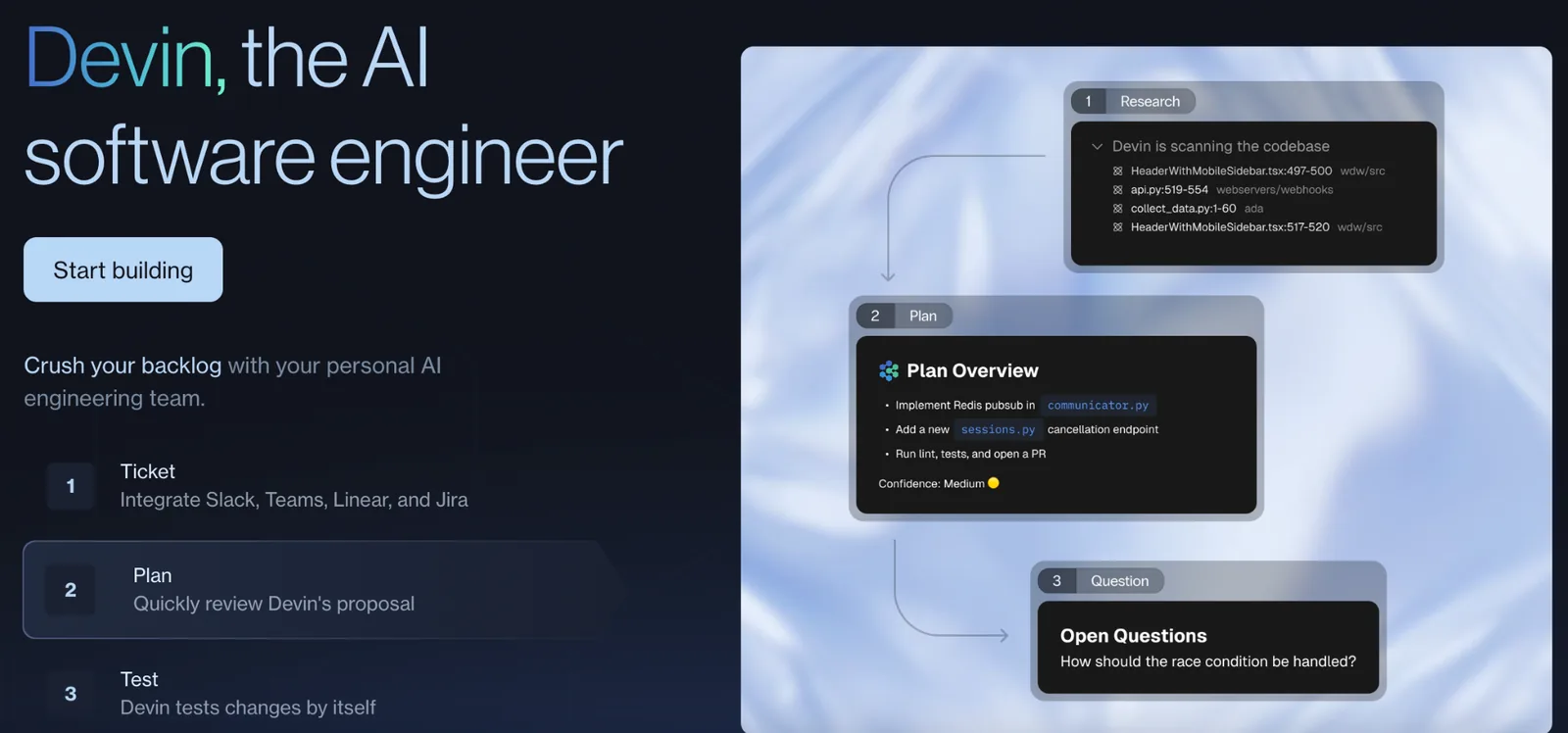
The gap between “AI assisted” and “AI autonomous” is wide, and it persists precisely in the places that matter most. The harder a task is to verify, the more it depends on design judgment or organizational history, the less confidently it can be handed off.
What the Evidence Actually Shows
The most useful way to evaluate autonomous software engineering is through what it has done in real production environments.
The Nubank case is instructive. The Brazilian fintech company had accumulated a monolithic ETL repository of over six million lines of code that needed to be split into smaller sub-modules after eight years of growth. The migration involved more than 100,000 data class implementations, with a projected timeline of 18 months using human engineers working manually.
Within weeks of deploying Devin, Nubank achieved a 12x efficiency improvement in engineering hours saved, with the migration completed in a fraction of the original timeline. A human engineer was kept in the loop to manage the project and approve changes, but the implementation itself was autonomous.
In another story, Goldman Sachs piloted Devin alongside its 12,000 human developers, with CIO Marco Argenti describing the potential as a 3x to 4x productivity gain over previous AI tools. He described a vision for a “hybrid workforce” where hundreds, potentially thousands, of autonomous agents work alongside human developers.

Infosys followed in January 2026 with what it described as one of the largest enterprise deployments of agentic software engineering to date, rolling out across banking, payments, capital markets, and other key verticals.
At this scale, in these environments, the question of whether autonomous software engineering works in production has largely been answered.
The AI Productivity Paradox
But the enterprise case studies tell only half the story. The other half comes from the data on what actually happens to delivery performance once these tools are in the hands of real engineering teams at scale.
The 2025 DORA Report surveyed nearly 5,000 technology professionals and reached a conclusion that most AI coverage glosses over: AI does not automatically improve software delivery. It amplifies whatever conditions already exist.
Teams with mature engineering practices and well-defined workflows are far more likely to turn AI-driven gains into real delivery improvements. Whilst teams with fragmented tooling and unclear processes are more likely to find that AI speeds up the accumulation of technical debt and adds instability to systems that were already fragile.
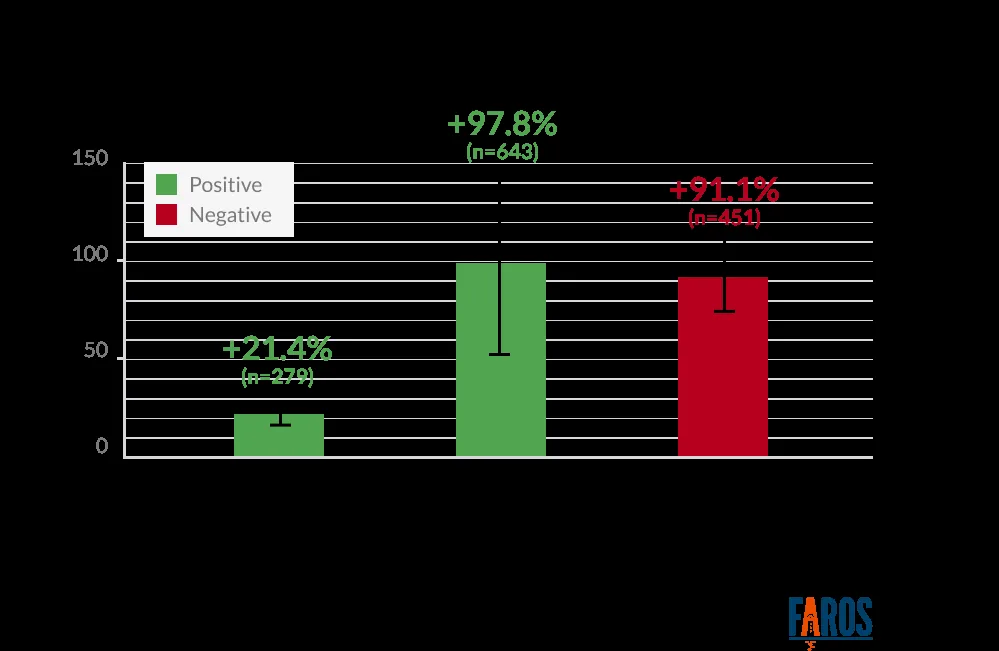
Faros AI’s telemetry analysis of over 10,000 developers confirmed the same dynamic from a different angle. AI coding assistants produced a 21% increase in task completion and a 98% increase in pull requests merged at the individual level.
But organizational delivery metrics, like lead time and change failure rate, stayed flat.
That’s because AI makes it easier to write and ship more code, but the rest of the system doesn’t speed up with it. So you end up with bigger review queues, slower testing, and bottlenecks further down the line that cancel out the gains.
At the end, engineers spend less time writing code and more time deciding what should be built, checking what agents have produced, and catching the mistakes that slip through precisely because the output looks finished and correct. The demand on human judgment does not shrink. In some ways, it gets harder.
What It Means for the People Doing the Work
The conversation about autonomous software engineering and jobs runs in two directions. While the full-replacement narrative overstates what is happening, the “nothing to worry about” narrative understates it.
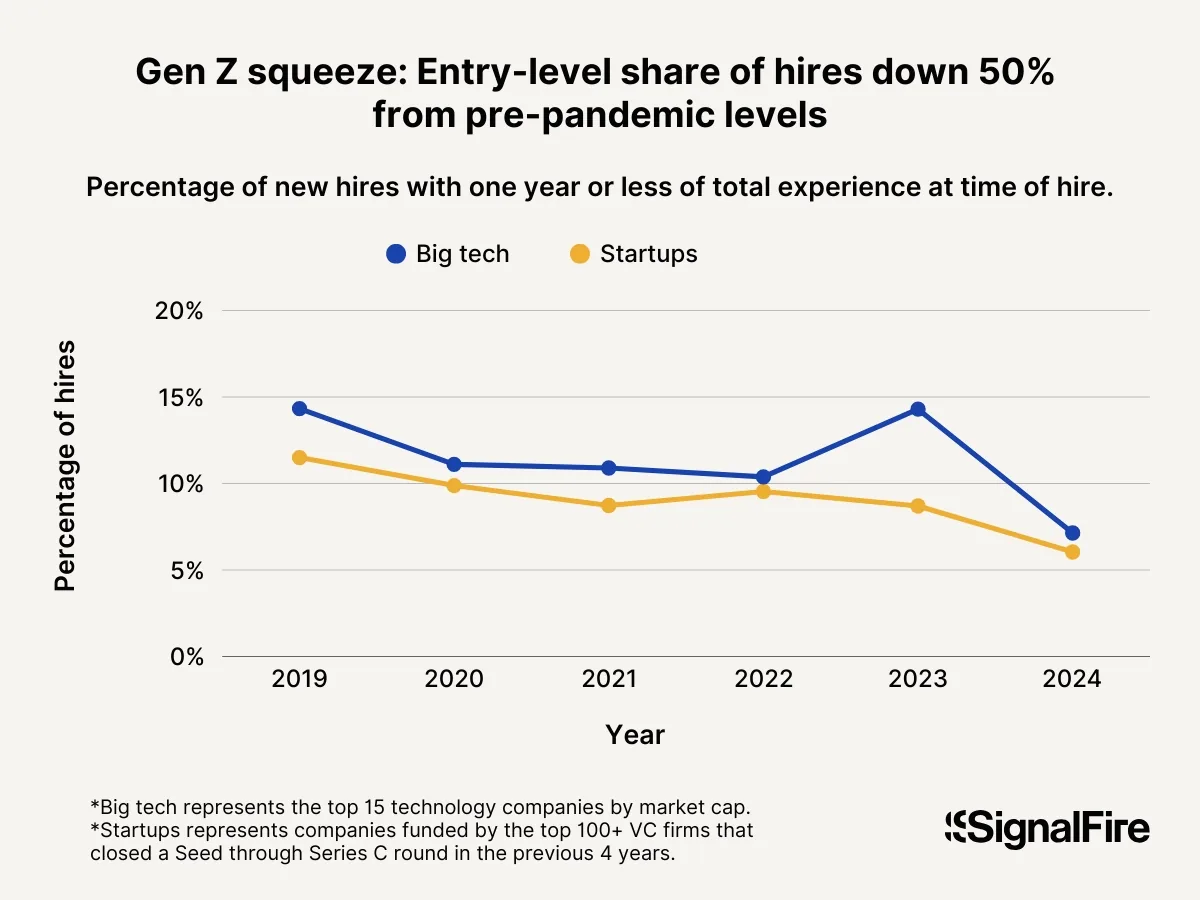
New graduates are feeling that shift most sharply. According to the SignalFire State of Tech Talent Report 2025, new grads now make up just 7% of Big Tech hires, down 25% from 2023 and more than 50% lower than pre-pandemic levels, while startups are hiring under 6%.
At the same time, even top computer science graduates are facing higher unemployment and more difficulty breaking into entry-level roles, as companies increasingly favor experienced engineers who can deliver immediate impact.
It’s not enough to just say that AI is replacing junior developers. We should frame it as displacement of a specific category of work. The tasks that used to serve as the entry point into software engineering, building out basic features, creating boilerplate, and fixing small bugs, are now being handled by autonomous agents and AI coding tools.
With fewer opportunities to learn through these foundational tasks, it becomes harder for new engineers to gain experience and grow into more advanced roles.
For senior engineers, the picture looks different. A single senior engineer working with these AI agents can now produce what previously required a small team. The accumulated judgment from years of system design, architecture decisions, and pattern recognition gets amplified when that experience is directing autonomous agents rather than being spent on boilerplate.
AI-native engineers are commanding the strongest compensation offers in the market right now, and the gap between those who have adapted and those who have not is widening.

The structural concern worth taking seriously is the pipeline problem. Today’s junior developers are tomorrow’s senior engineers and technical leaders. An industry that stops training its own replacements creates a leadership vacuum five to ten years from now.
Organizations deploying autonomous software engineering at scale will eventually need to answer for that, not from a regulatory standpoint necessarily, but from a talent sustainability one.
So Where Does That Leave Engineering Teams?
The question most CTOs and engineering leaders are wrestling with right now is not whether autonomous software engineering works. The evidence on that is clear enough.
It works on the right problems, in the right organizational conditions, with the right governance around it. The harder question is whether their organization has those conditions in place, and most are honest enough to admit they are not sure.
That uncertainty is not a reason to wait. The gap between teams that are building this capacity deliberately and those still running experiments without infrastructure around them is widening every quarter.
The Goldman Sachs deployment did not produce results because they deployed the most agents. It produced results because they configured the environment, defined what success looked like, and kept humans in the loop on the decisions that mattered.
That is the work most organizations have not done yet, and it is harder than selecting a tool. And that’s where GAP comes in.
GAP’s AI Acceleration Workshops help engineering organizations work through exactly this: identifying where autonomous engineering creates genuine leverage, building the governance infrastructure that makes deployment safe, and defining the conditions under which results are actually reproducible.
For teams that need to validate the approach before committing to it at scale, Validate:AI provides a structured path from proof of concept to production. If your team is at that decision point, a conversation with a GAP expert is a good place to start.


