
For much of the AI boom, the conversation focused on capability. The question was what AI could do, where it could be applied and how quickly it could deliver value.
Now, attention is being drawn to a different question: what does it cost to run AI at scale?
As models grow more autonomous, agentic systems can now plan, execute, evaluate results and iterate with minimal human involvement. While that expands what organizations can automate, it also increases the amount of compute consumed behind the scenes. Effective AI cost optimization requires understanding not just what you’re spending, but why AI tokens accumulate so quickly in these environments.
Uber’s experience illustrates the challenge. In April 2026, the company revealed it had exhausted its annual budget for AI coding tools in just four months.
Thousands of engineers were using tools such as Claude Code and Cursor, while leadership struggled to connect rising token consumption to a proportional increase in business value.
Uber is hardly alone. Across industries, executives are discovering that the economics of AI can look very different in production.
In this article, we’ll explore why AI costs escalate, where token spend accumulates and the strategies organizations are using to keep expenses under control without sacrificing outcomes.
Why AI Spending Is Difficult to Predict
The scale of the problem becomes easier to understand when you look at how AI is being used in practice.
Unlike traditional software, where infrastructure requirements are often easier to estimate, AI consumption can vary significantly depending on the complexity of a task, the amount of context provided, the models involved and the path taken to reach a result.
In May 2026, software engineer Peter Steinberger shared the costs of running approximately 100 codex instances on his OpenClaw project. Over a 30-day period, the agents generated more than 603 billion tokens and 7.6 million requests, resulting in over $1.3 million in API spending.
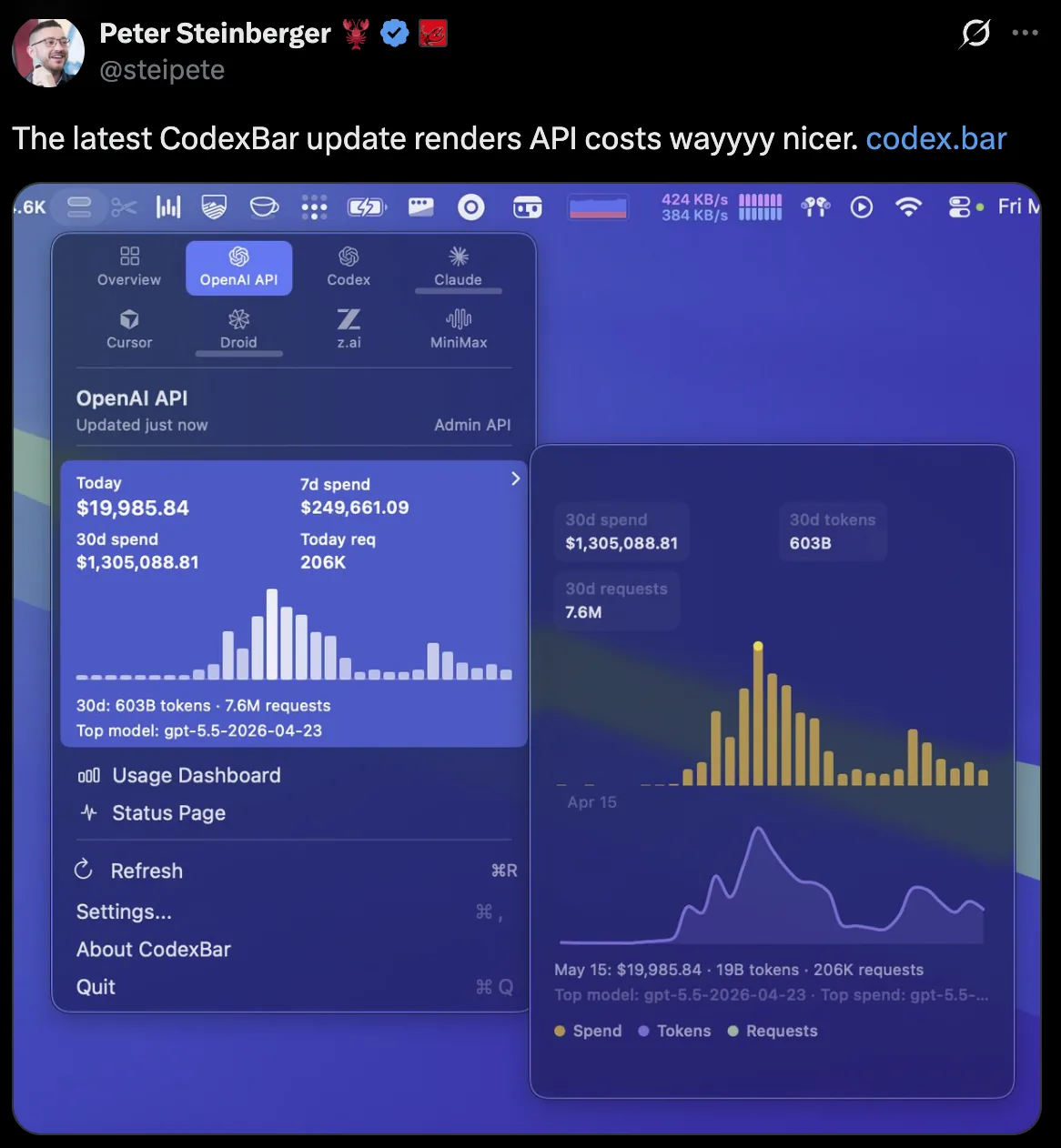
Source: X
Steinberger later noted that much of the spending was tied to a high-rate “Fast Mode” configuration. Disabling that single setting would have reduced costs by roughly 70%.
The example highlights a common pattern in enterprise AI.
Runaway spending is often driven less by the model itself than by configuration choices, architectural decisions and defaults that remain unnoticed until the bill arrives. This is why LLM cost optimization is increasingly treated as an architecture discipline, not a procurement problem.
Why Agentic Systems Consume So Many Tokens
To understand where costs come from, it helps to look at how agentic systems actually work.
Every Step Carries the Weight of the Last
Most large language model APIs are stateless, meaning they do not remember previous interactions.
To maintain context, agents resend conversation history, instructions, tool outputs and other relevant information with every request. As a task progresses, that context grows.
A recent study measured just how large that gap gets, finding that agentic coding tasks consumed roughly 1,200x more tokens than a multi-turn chat and around 3,500x more than a single-round reasoning task.
Larger context windows can improve performance, but they also increase AI token consumption at every step of the workflow.
One Request Can Trigger Dozens More
What looks like a single request from a user’s perspective often involves many separate actions behind the scenes.
An agent may search documentation, retrieve files, query databases, call APIs, execute code, evaluate results, revise its approach and repeat the process several times before returning an answer.
Each additional step generates more model interactions and more token consumption. By the time a task is complete, a seemingly simple request may have triggered dozens of separate operations.
Longer Tasks Become More Expensive
Simple tasks are usually inexpensive. Costs rise when agents are given objectives that require planning, execution, evaluation and iteration over many steps.
An agent that spends several minutes researching options, testing approaches, reviewing outputs and refining its work can consume significantly more tokens than a traditional chat interaction.
Basically, the longer the workflow, the more opportunities there are for costs to accumulate.
Agents Don’t Always Know When to Stop
Agents do not always take the shortest path to a solution. A multistep agent can fall into a recursive loop, over-query a system or quietly expand a task well beyond its original scope, with each detour spending more tokens.
Failed tool calls, API timeouts, permission errors and unexpected outputs can also trigger retries or force an agent to revisit previous steps.
These additional requests may be invisible to users, but they still consume AI tokens and contribute to the final bill.
More Agents, More Cost
Multi-agent systems are becoming increasingly common. One agent may plan a task, another may execute it, a third may review the results, and a fourth may validate the final output.
These architectures can improve reliability and performance, but they also multiply the number of model interactions required to complete a piece of work.
Every additional agent introduces another layer of token consumption, making AI spend management harder to predict and control.
The Costs Beyond the Token Bill
Part of the challenge with AI spending is not simply that it can become expensive. It is that many of the most important costs are difficult to measure, predict or attribute.
One of the biggest gaps is between consumption and value. Organizations can track token usage, API calls and monthly spend with precision, but those metrics reveal little about business outcomes. It’s not easy to determine if additional tokens are producing a proportional increase in useful work.
Forecasting presents another challenge. Research has shown that token usage is highly variable and stochastic, with two runs of the identical task differing by as much as 30 times.
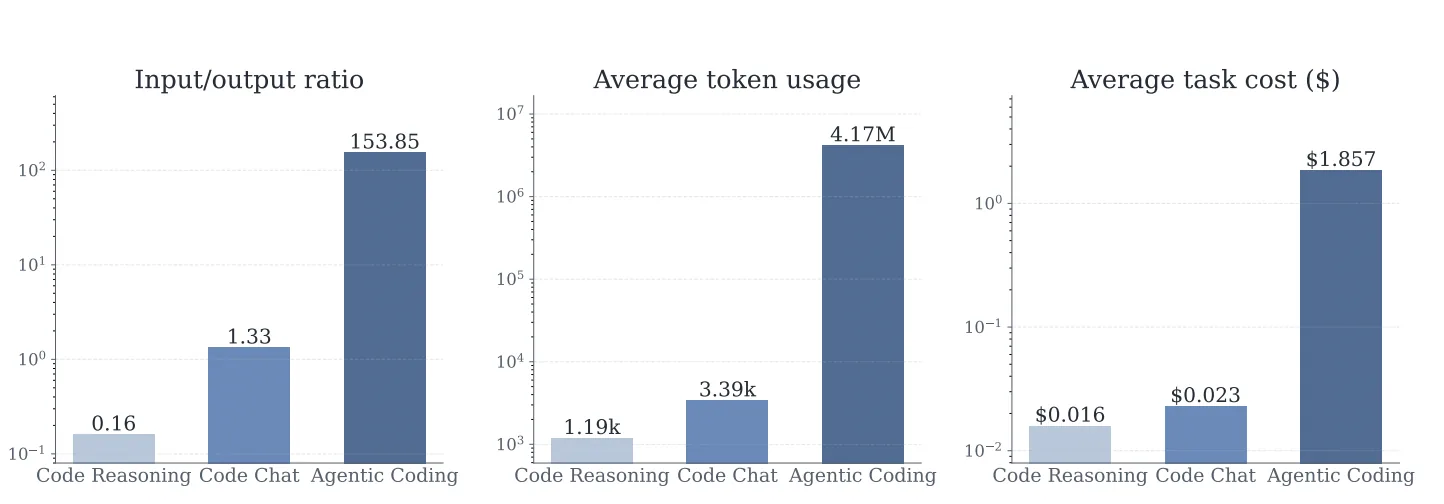
Source: Arxiv
The study also found that consuming more tokens did not necessarily lead to better results. In other words, spending more does not automatically mean getting more value.
There is also the question of dependency. Many organizations build around a single provider’s models, APIs and pricing structure. The approach accelerates development but can become costly over time. Changes to pricing, model availability or platform capabilities may leave teams facing significant migration effort simply to regain flexibility.
For many organizations, these challenges prove harder to manage than the token bill itself.
The issue is not just controlling spend, but understanding what the organization is getting in return, predicting future costs with reasonable confidence and maintaining enough flexibility to adapt as the market evolves.
How Companies Are Bringing AI Costs Under Control
The good news is that runaway AI costs are rarely inevitable.
In many cases, the biggest drivers of spend are architectural and operational decisions that can be changed without reducing the value users receive.
Organizations that successfully control costs tend to focus on a handful of high-impact areas.
Route Tasks to the Right-Sized Model
One of the most effective ways to reduce AI spending is matching model capability to the task being performed.
Not every request requires a frontier model. Tasks such as classification, summarization, routing and information extraction can often be handled by smaller and less expensive models, while more capable models are reserved for complex reasoning or high-stakes decisions.
This allows organizations to reduce costs significantly without sacrificing performance where it matters most. Model routing is one of the highest-leverage levers available in LLM cost optimization and one of the easiest to implement incrementally.
Reduce Context Bloat
More context is not always better.
Teams often pass entire documents, lengthy conversation histories or large knowledge-base excerpts to models when only a small portion of that information is relevant. Because every AI token carries a cost, unnecessary context can quickly become an expensive habit.
Techniques such as context pruning, retrieval-based approaches and sliding windows help reduce token consumption without affecting output quality.
Cache Repeated Context
Many AI applications repeatedly send the same instructions, system prompts and reference information with every request.
Prompt caching reduces the cost of processing this repeated content by allowing providers to reuse previously processed context rather than treating every request as entirely new.
For applications built around stable prompts or recurring workflows, prompt caching can be one of the simplest ways to reduce spend. Most major API providers support it natively, yet it remains one of the most underused levers in enterprise AI cost optimization.
Set Limits Before You Need Them
Many of the largest AI bills come from a small number of unusually expensive sessions, workflows or users.
Usage caps, spending thresholds, rate limits and budget alerts help prevent isolated incidents from becoming major financial surprises.
These controls are particularly important for autonomous systems, where costs can accumulate rapidly without direct human oversight. They are also a core component of mature AI spend management, something most organizations put in place only after their first unexpected bill.
Measure Value, Not Just Usage
Cost optimization is ultimately a business problem rather than a token problem.
Organizations that focus exclusively on reducing consumption risk optimizing for the wrong outcome. The goal is to understand which workloads generate meaningful value and which do not.
Once that visibility exists, teams can make informed decisions about where higher spending is justified and where efficiency improvements should be prioritized.
Concluding Thoughts
The instinctive response to rising AI bills is often to blame the model. In practice, runaway costs are usually the result of how a system is designed, configured and governed.
The good news is that many of the biggest drivers of spend are within an organization’s control. Controlling agent costs is, at bottom, an architecture and engineering discipline.
At GAP, we help organizations design, build and modernize AI systems with cost discipline built in from the start, from model selection and orchestration to evaluation, observability and governance.
If your AI bill is climbing faster than the value you can point to, or you want to deploy agents without that risk in the first place, GAP’s AI Acceleration Workshops are designed to help you find where the spend is going and where the value actually is before you build.


