
AI has become a standard part of how software gets built.
From startups to Fortune 500 companies, we’re seeing more code being produced (with AI assistance) than at any point in software history. What began as an experimental productivity tool has become embedded in day-to-day development workflows across the industry. As agentic workflows become standard, so does the need for structured oversight of what those workflows produce.
The numbers reflect just how widespread adoption has become.
In Stack Overflow’s 2025 Developer Survey, approx. 84% of developers reported using or planning to use AI tools in their work, up from 76% a year earlier.
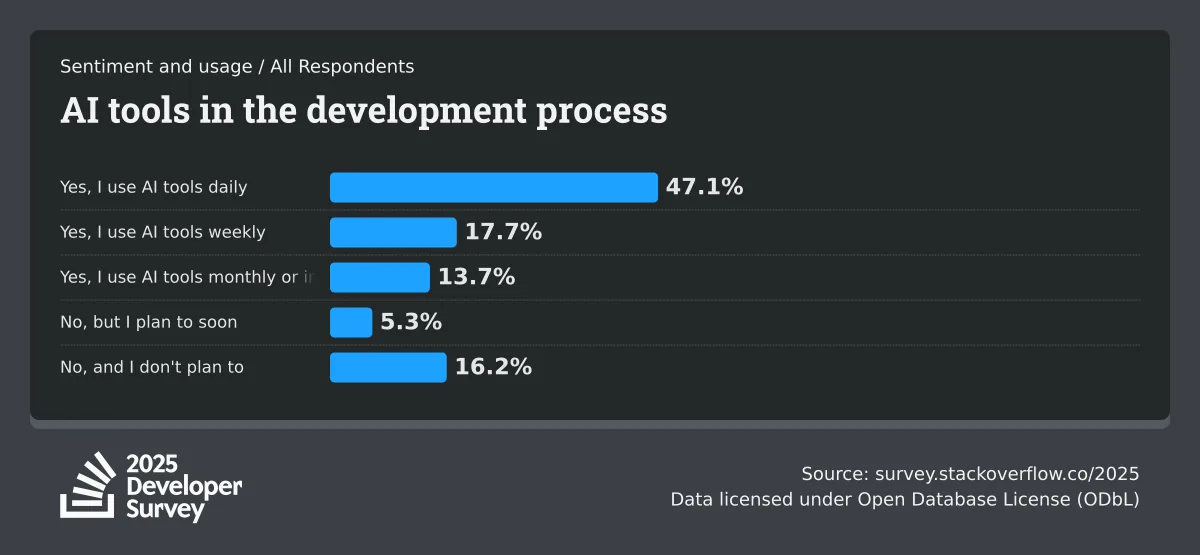
Source: Stack Overflow
Other research suggests that, in some environments, 61% of organisational code is now AI-generated or AI-assisted, while more than half of developers say AI has improved their productivity.
The benefits are clear, yet a growing body of research points to trade-offs. The same tools that help teams produce code faster may also be introducing new quality challenges.
GitClear’s analysis of 211 million changed lines of code found declining refactoring activity alongside an eightfold increase in duplicated code blocks, suggesting AI-assisted development may be accelerating code creation faster than teams can maintain it.
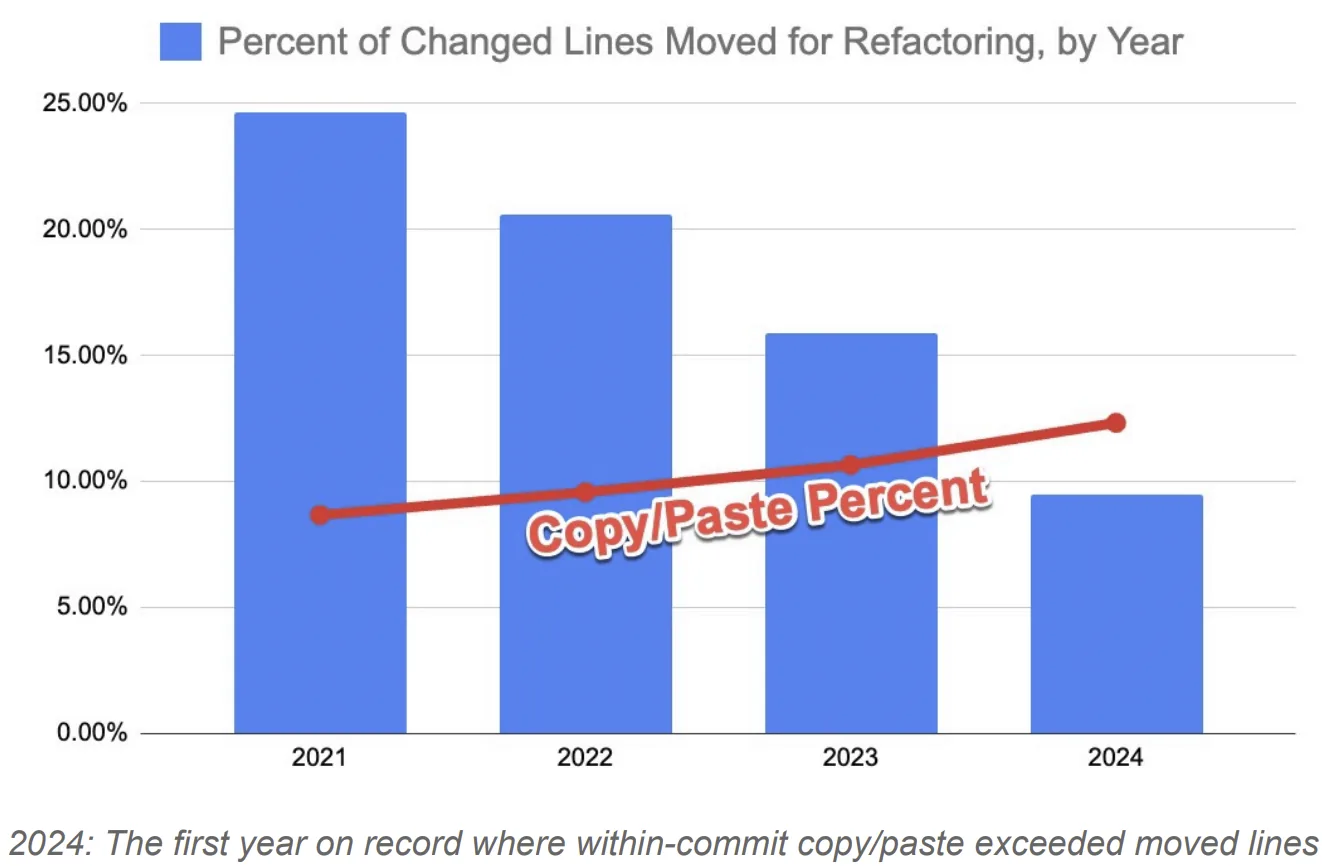
Source: GitClear
Over time, these patterns can make systems harder to understand, increase maintenance overhead, complicate testing, and contribute to the accumulation of AI technical debt – a growing cost for teams shipping AI-assisted code at scale
The impact often emerges months later in the form of slower development cycles, more fragile releases, and growing effort spent managing complexity instead of delivering new features.
As AI becomes a larger part of the software delivery process, code quality can no longer be treated as an afterthought.
Why More Code Creates More Risk
The challenge with agentic AI workflows is not that they produce bad code. It is that they produce so much code, so quickly, that existing quality processes struggle to keep pace.
In a traditional workflow, developers spend a significant amount of time deciding what to build, writing code, reviewing changes and refining implementations.
Agentic systems compress much of the creation phase, allowing features to be built faster.
The problem here is that code generation is only one part of software development. Every line of code still needs to be reviewed, tested, integrated, documented, monitored and maintained.
So while AI reduces the effort required to create code, it does not eliminate the effort required to manage it. As output increases, review processes become a bottleneck.
Teams are left evaluating a growing volume of changes, often under the same time and resource constraints as before.
Why a Better Model Will Not Save You
It is tempting to assume this problem will largely disappear as models improve. If today’s systems create quality issues, then tomorrow’s systems should create fewer of them.
The reality is more complicated. Many of the challenges introduced by AI-generated code are not the result of weak models but missing context.
A model has no lasting understanding of the codebase it is working within. It does not know the architectural decisions behind the system, the conventions a team follows or the trade-offs that shaped previous decisions. It works only with the context it is given.
That means code can be technically correct while still being a poor fit for the system.
Better models may generate cleaner code and make fewer mistakes, but they do not automatically acquire the context needed to judge whether a change belongs within a particular codebase.
The result is often visible in the quality of the code that gets shipped. A study by CodeRabbit found AI-generated pull requests contained 1.7 times more issues overall, with logic and correctness errors occurring 75% more frequently than human baseline.
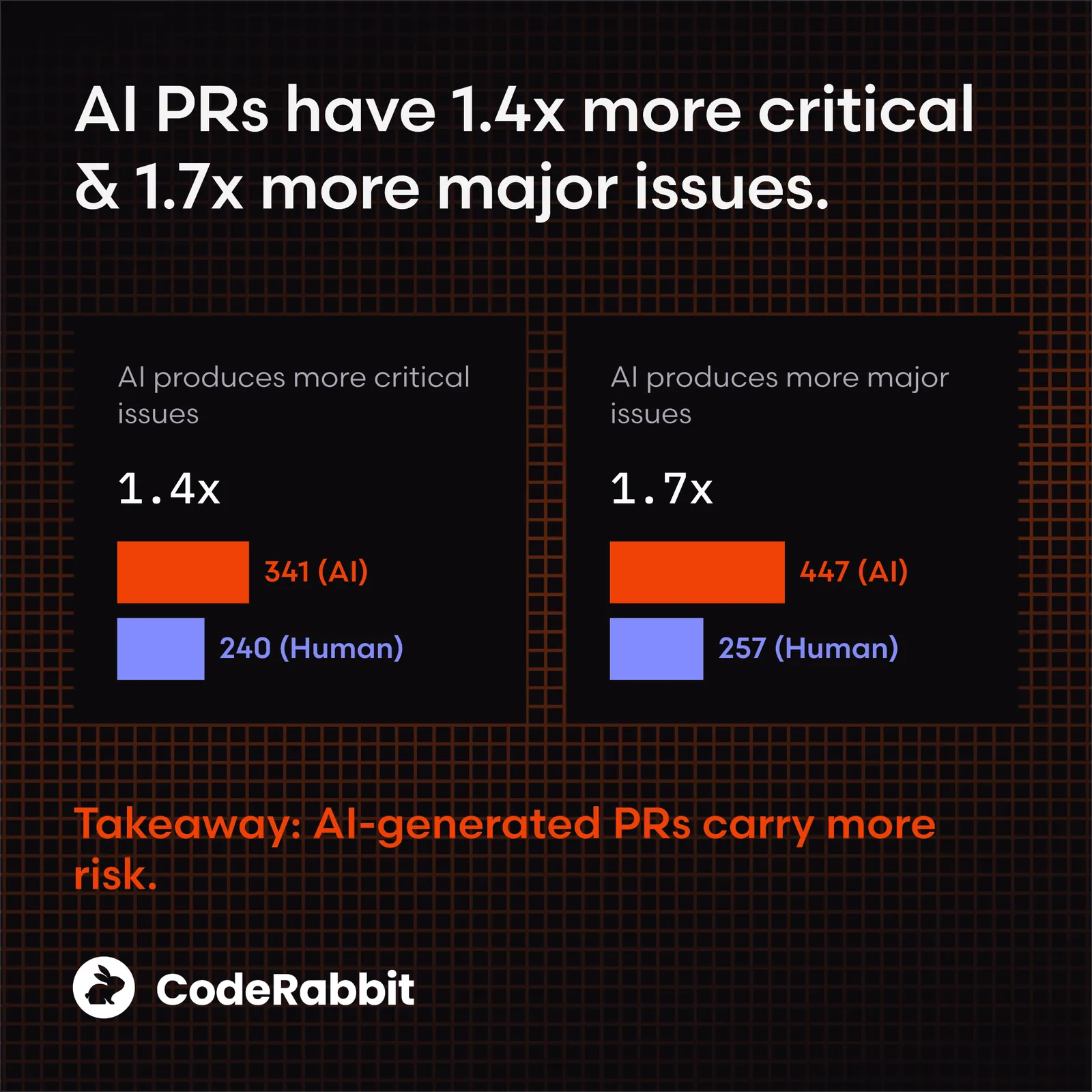
Source: CodeRabbit
None of this suggests that AI-generated code is inherently unreliable or that engineering teams should avoid using it.
The lesson is that code quality does not emerge automatically from better generation. It depends on the systems, processes, and AI code review practices surrounding the model, which means organizations have far more influence over the outcome than they might initially assume.
The challenge is how to capture the productivity benefits of AI without allowing quality to erode as output scales.
The Playbook for Keeping AI Code Quality High
The following practices help teams maintain quality as AI-generated code becomes a larger part of the development process.
-
Treat Agent Output as a First Draft
One of the easiest ways for quality to deteriorate is to treat AI-generated code as finished work rather than a starting point.
The role of review changes in an agentic workflow. Instead of spending time checking formatting, syntax or other issues that automated code review tools can catch reliably, reviewers should focus on questions that require human judgment.
Does the change fit the architecture? Does it follow established patterns? Does it make the system easier or harder to maintain? Are there trade-offs the model could not reasonably understand from the context it was given?
Treating agent output as a first draft helps ensure that human attention is spent where it creates the most value rather than where automation already performs well.
-
Track AI Defects as a Metric, Not a One-Off Fix
Many teams fix AI-related mistakes as they appear and move on. The immediate problem gets resolved, but little attention is paid to whether similar issues are showing up elsewhere.
This makes recurring patterns easy to miss. One mistake may not mean much on its own, but repeated mistakes often point to a deeper issue in the prompt, the context provided to the model or the review process itself.
Tracking AI-attributed defects, regressions or review outcomes makes it easier to identify where generated code is consistently creating risk and where existing controls may be falling short. Incorporating AI code analysis into this process, whether through tooling or manual review logs, surfaces patterns that a one-off fix approach will always miss.
Once those patterns become visible, quality becomes something that can be measured and improved rather than a vague concern raised after something goes wrong.
-
Give the Model the Context It Cannot Infer
Many failures blamed on the model are failures of context. An agent works only from what it is given, and it cannot infer architectural decisions, business rules or team conventions that were never written down.
That makes context one of the highest-leverage inputs to quality. Teams that supply existing patterns, explicit constraints and clear implementation requirements get materially better output than teams relying on a thin prompt.
The more context a model has about how a system works, the better its chances of producing code that fits naturally within it. This is especially important in agentic workflow environments, where the model operates across multiple steps with limited human checkpoints.
-
Stop Treating a Green Build as a Quality Signal
One of the most common mistakes in AI-assisted development is treating code that compiles and passes its tests as evidence that it is production-ready.
Automated code review tests confirm that code behaves as expected under specific conditions, but they do not tell you whether the implementation fits the architecture or creates maintenance challenges later.
This helps explain a growing frustration among development teams. Roughly two-thirds of developers report spending meaningful time correcting AI-generated output that is almost right.
Quality extends beyond correctness to include maintainability, consistency and long-term fit within the system. Without a deliberate AI code review layer on top of automated checks, teams are left with a false sense of confidence about what they’re shipping.
How GAP Helps Teams Put This in Place
Most teams already know that review, measurement and context are what keep quality high.
The difficulty is holding to them once output scales and deadlines press, when the quickest path is to wave through code that looks finished.
This is the work we do at GAP. We build agentic workflows that meet your quality standards, with AI code review processes embedded inside your team so those standards hold in everyday work.
If quality already feels like it is slipping, or you want to put this discipline in place before it does, reach out to an expert.


