
This article was co-authored with Nathan Smith and Nick De Luca
Over the past decade, self check-out and ordering kiosks have become increasingly prevalent, and the Covid-19 pandemic only quickened their adoption across the food service and hospitality sectors. One of the key draws of a kiosk (beyond avoiding people, of course) is a large touch-screen, which when paired with an intuitive interface can provide a quick and easy ordering process. Although self service via touch screens is convenient, there are certainly some downsides to this. Many people touch these kiosks throughout the day, leading them to be very unsanitary, with the pandemic only strengthening fears in some people. Another drawback is a kiosk’s lack of flexibility compared to interacting with a human. Users with a language barrier or physical disability may experience more difficulty with these interfaces.
One promising way to build on the touch-screen kiosk is to build a multimodal interface – which processes two or more combined user inputs, such as touch, speech, gaze, or body movements. These additional inputs can provide for a more flexible and inclusive experience for users, and more closely replicate the experience of interacting with a person.
In this article, we will continue our series on Google’s MediaPipe, exploring how we might implement a multimodal user interface to allow users to navigate a kiosk through the use of hand gestures. Our prototypes will be developed in Python for a number of reasons – as covered in our last article, we faced significant hurdles getting MediaPipe for Android working on a variety of systems, especially when trying to run applications on an emulator. Additionally, the development community for MediaPipe is significantly larger for Python than with Android, iOS, Javascript, or others, so working with Python provided us far more examples and tutorials to work from.
MediaPipe Under the Hood
In our previous article, we discussed how Mediapipe’s Hands solution uses machine learning to register a multitude of landmarks on a person’s hand. We also make use of OpenCV to implement live video recording in conjunction with MediaPipe’s image processing. The following pseudocode gives insight into how we go through and draw the landmarks that have been detected.
detectLandMarks(image, hands):
# Image to output
new_image = image.copy()
# Converting image to RGB
imgRGB = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = hands.process(imgRGB)
# Check if landmarks are found
if results.multi_hand_landmarks:
# Iterate over the found hands
for hand_landmarks in results.multi_hand_landmarks:
# Draw the landmark onto the image
mp_drawing.draw_landmarks(image = output_image, landmark_list = hand_landmarks)
return output_image
The function starts by retrieving an image, and then iterates through each landmark, drawing it if it is visible in the camera’s view. A before and after photo is then produced. The images below are taken in rather poor lighting, however, the incredible accuracy of the landmark and connection placement can still be seen.

Another important bonus with the Hands solution is that even occluded hand landmarks can be placed very accurately. For example, in the image below, we will see how the program pinpoints hidden landmarks on a fist.
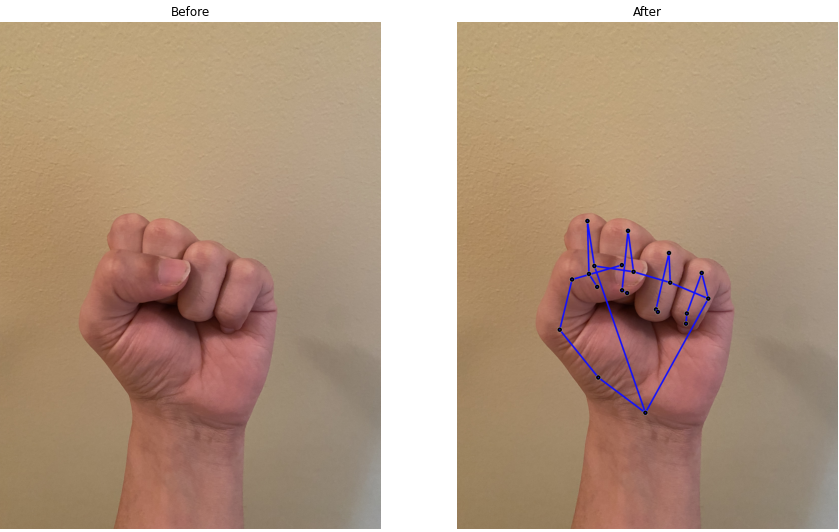
Even with gestures where some hand landmarks may be hidden from the human eye, MediaPipe’s Hands solution still boasts extremely accurate landmark placement and prediction.
As a first experiment in gesture recognition, we’ll build a simple gesture recognition app that doesn’t make use of any further machine learning. This can be done by keeping track of the relative positioning of different landmarks on the hand, which will tell us if certain fingers are being extended or making any other sort of motion.
Simple Gesture Recognition: Counting Fingers
As a first prototype of gesture recognition without machine learning, we implemented a simple finger counting application. With the help of an excellent tutorial, we developed the application in Python using Jupyter Notebook, a web-based development environment that makes rapid prototyping fast and easy.

Above are examples of this prototype in action. This is achieved by utilizing the hand landmarks that we detected earlier. Specifically, through the landmarks, we can determine whether or not fingers are being raised, and if they are, add them to our finger count.
We determine the state of the fingers by comparing the coordinates of different landmarks. For every finger except the thumb, this is determined by comparing the y coordinate of each fingertip with the y coordinate of its corresponding finger PIP (short for Proximal Inter-Phalangeal Joint, the second joint down from your finger tip). Implementing this was relatively simple using MediaPipe Hands’ multi_hand_landmarks values, which we can individually fetch the x and y coordinates from for comparison. In the following code snippet, we iterate through the four non-thumb finger tips, and test if the tip landmarks are higher in the image than the PIP landmarks, and if so, iterate the counter.
# Perform the Hands Landmarks Detection.
results = hands.process(imgRGB)
# Store the indexes of the tips landmarks of each finger in a list.
fingers_tips_ids = [mp_hands.HandLandmark.INDEX_FINGER_TIP, mp_hands.HandLandmark.MIDDLE_FINGER_TIP, mp_hands.HandLandmark.RING_FINGER_TIP, mp_hands.HandLandmark.PINKY_TIP]
# Retrieve the landmarks of the found hand.
hand_landmarks = results.multi_hand_landmarks[hand_index]
# Iterate over the indexes of the tips landmarks of each finger.
for tip_index in fingers_tips_ids:
# Retrieve the label (i.e., index, middle, etc.) of the finger.
finger_name = tip_index.name.split("_")[0]
# Check if the finger is up by comparing the y-coordinates of the tip and pip landmarks.
if (hand_landmarks.landmark[tip_index].y < hand_landmarks.landmark[tip_index - 2].y):
# Update the status of the finger in the dictionary to true.
fingers_statuses[hand_label.upper()+"_"+finger_name] = True
# Increment the count of the fingers up on the hand by 1.
count[hand_label.upper()] += 1
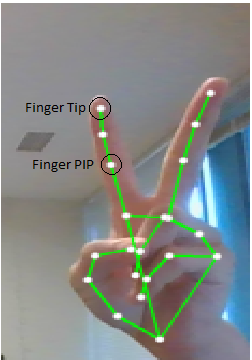
For the thumb, rather than comparing the y coordinate of its tip and PIP, we take a different approach. As the thumb lacks a PIP, we will be using the coordinate of its MCP (short for Metacarpophalangeal Joint, the base joint of the thumb).

Also, rather than comparing the thumb tip’s y coordinate with the thumb MCP’s y coordinate, we compare their x coordinates. As we can observe in the above image, the thumb tip is still above the thumb MCP when it is not extended. However, notice that the thumb tip on the right hand is left of the MCP when it is extended, and right of the MCP when it is not. Thus we consider the thumb raised when the thump tip’s x coordinate is less than (or further left than) the thumb MCP’s x coordinate on the right hand. This is reversed for the left hand. Note that these tests assume the palm of the hand is facing towards the camera, and would need to be reversed if the hand was facing the other direction.
# Check if the thumb is up by comparing the hand label and the x-coordinates of the retrieved landmarks.
if (hand_label=='Right' and (thumb_tip_x < thumb_mcp_x)) or (hand_label=='Left' and (thumb_tip_x > thumb_mcp_x)):
# Update the status of the thumb in the dictionary to true.
fingers_statuses[hand_label.upper()+"_THUMB"] = True
# Increment the count of fingers up on the hand by 1.
count[hand_label.upper()] += 1
Unique Gesture Recognition with Hand Landmarks
Next, we expanded on our finger counting prototype, using the relative positioning of hand landmarks to recognize more advanced gestures. This app utilizes some of the same code from the finger counter to determine the gesture being made. The separate gestures are differentiated by the number of fingers being raised, as well as which specific fingers are being raised. For example, the Open Hand gesture is recognized when all five fingers are raised. The L sign gesture on the other hand is recognized when two fingers are raised, and those two fingers are the thumb and the index finger.

As another example, we could use the following to predict if the user is making the peace sign, or V sign, with their fingers:
# Check if the number of fingers up is 2, and that the raised fingers are the middle and index.
if count[hand_label] == 2 and fingers_statuses[hand_label+'_MIDDLE'] and fingers_statuses[hand_label+'_INDEX']:
# Update the gesture value of the hand to the V sign.
hands_gestures[hand_label] = "V SIGN"
Full Body Tracking with MediaPipe Holistic
Mediapipe’s Hands solution isn’t the only way gestures can be recognized, and there are a plethora of machine learning libraries available that have similar functionality. With this in mind, we wanted to briefly explore solutions that not only recognize hand gestures, but also arm, body, and facial gestures. While the applications of full-body tracking for a kiosk are less obvious, being able to detect facial expressions provides new possibilities, while detecting the angles of your arms over time could help in detecting more full-body gestures such as waving.
The Mediapipe Holistic solution provides full-body tracking, including face landmarks, the pose of arms and legs, and the previously discussed hand tracking. Here are some especially terrifying pictures we took after getting the solution running.
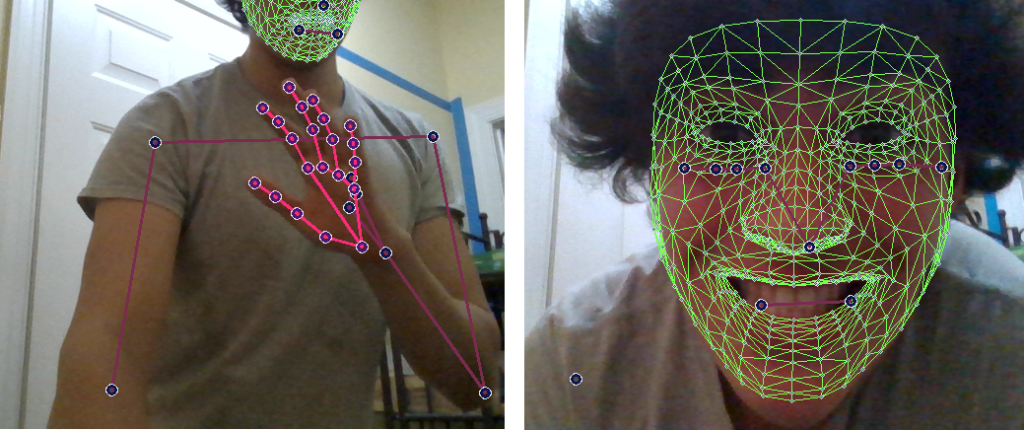
While the specifics of this prototype are beyond this article’s scope, we went through an excellent tutorial linked here that covers the detection of face, body and hand landmarks, collecting examples of different gestures to build a dataset, and then training on that dataset using TensorFlow to build a model that predicts gestures. For a review of TensorFlow and neural networks in another application, we recommend our series on TensorFlow for time-series prediction, which provides developers with no prior experience in machine learning a walkthrough on how to build their first model.
As covered in that series, we began by building a labeled dataset, which in this case is a series of images where the coordinates of face, body, and hand landmarks are recorded, as well as a label of what the gesture in the picture is, such as “hello” or “thanks”. We then trained an LSTM (Long Short Term Memory Network) model, which accepted a picture with all of MediaPipe’s annotated landmarks as input, and produced a gesture prediction as the output. By following the tutorial, we were able to produce live gestures predictions within a video feed.

While we did not have time to expand this solution beyond the tutorial, this prototype demonstrates that full-body gesture recognition is also very viable with MediaPipe, and could potentially open up our project to recognize a larger array of gestures.
Conclusion
After switching to Python and Jupyter Notebook, we were able to rapidly prototype gesture recognition applications via a more streamlined development environment and a wealth of online resources. Using MediaPipe’s landmark detection, we were able to predict gestures simply through the relative positioning of hand landmarks, without any further machine learning. We also found that more advanced gesture detection with TensorFlow could also be implemented without personal knowledge in machine learning, as there are many written and video resources on how to train a neural network and generate live gesture predictions.
These experiments have left us confident that MediaPipe, combined with a touch screen device such as an Android phone, can produce accurate multimodal interfaces. In the future we’ll continue to explore this topic, and aim to develop an Android application that allows users to select options via both touch and hand gestures.


