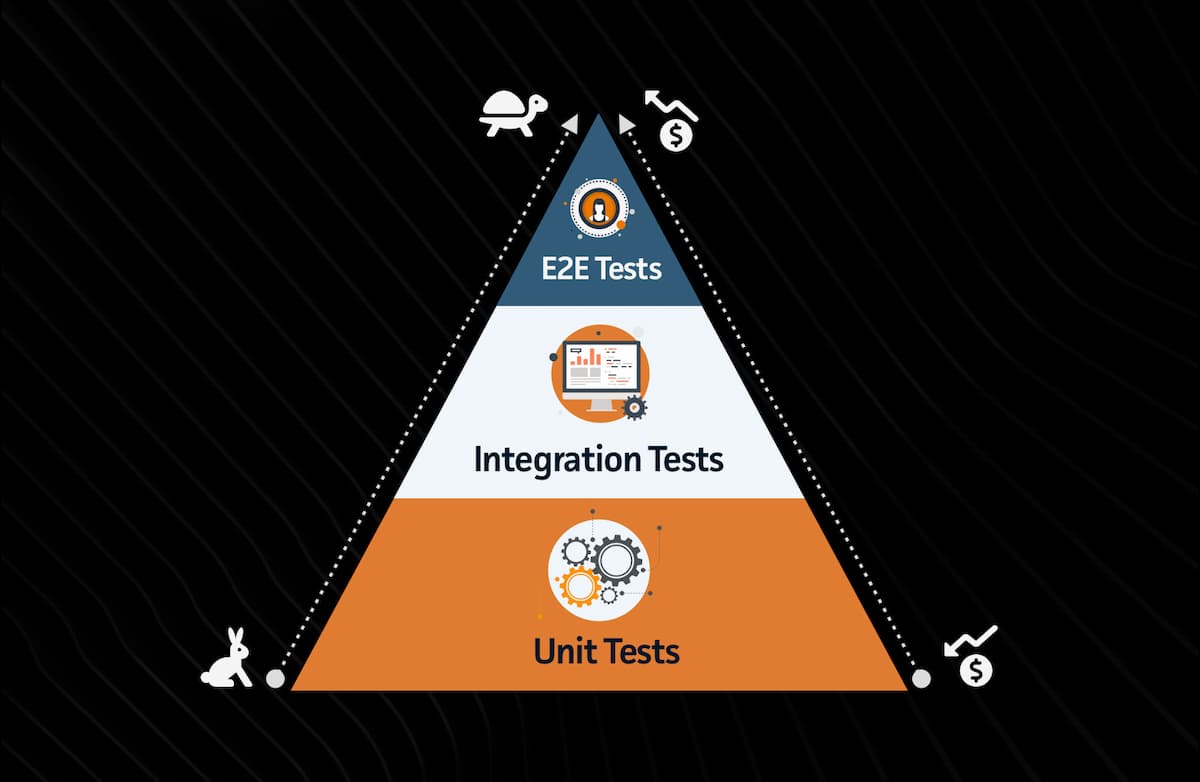
Automation is an important part of enhancing the software quality process, and there are a multitude of tools available to ensure that bug-free products are delivered to the client. End-To-End (E2E tests) testing is just one of the many available strategies that quality analysts employ to ensure a solid application is delivered.
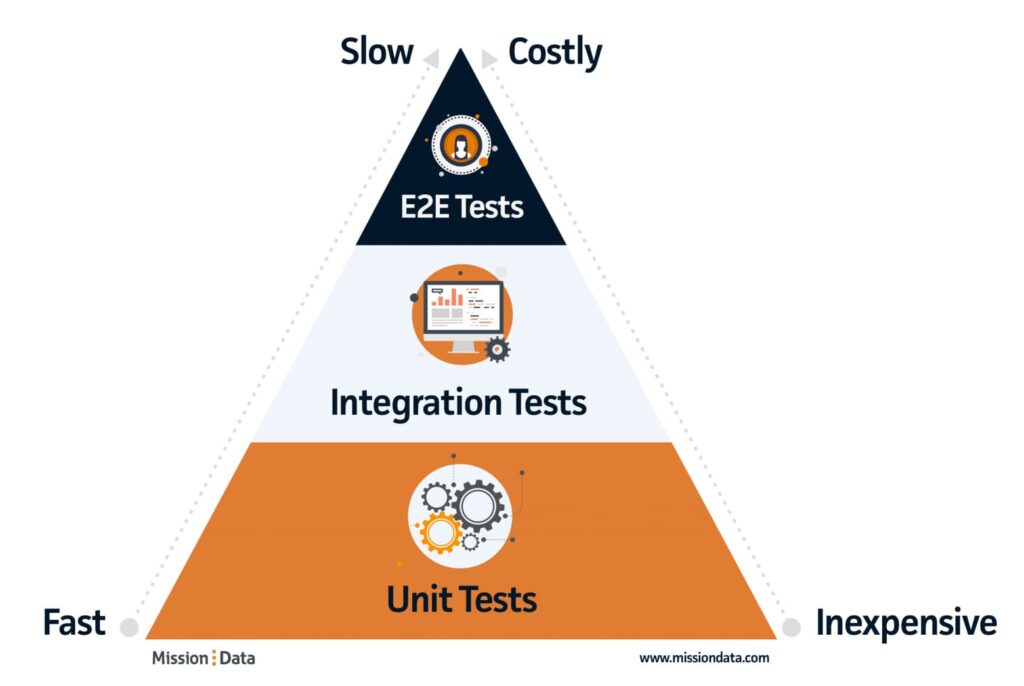
In theory, it’s a good idea for E2E tests to focus on what a user would be doing when interacting with your application. After all, focusing on “real world” scenarios is going to give the best insights into possible problems a user may encounter. However, this isn’t without its drawbacks. Below we discuss those disadvantages and how to mitigate them.
E2E Tests are Time Consuming
This is true in both how difficult they are to write AND run. E2E processes take longer to write compared to other forms, partly because the test must pass through each step a user would take. Sometimes this will involve spanning multiple views and user stories, adding to their complexity and run-time.
Speaking of run-time, E2E tests are almost always the slowest. A browser instance must be created and each step ran as if the user was using the application. This can be mitigated somewhat by using a headless browser, removing the need to render time-consuming views. Be warned however that headless browsers have disadvantages of their own, such as flaky behavior when testing against a real browser.
So what is the solution to this?
Following the testing pyramid, we need to first ensure that E2E tests make up the smallest part of our testing framework. Doing so will reduce total run-time overall due to the slowness of the E2E method.
Avoid Duplication
Keeping things DRY is also a hugely important part of reducing the run-time and complexity of E2E tests. For example, let’s take a look at a test that examines the required “Login” functionality using the Cypress.io framework. We chose to stick with the Cypress framework due to its easy integration into most common codebases, along with its built-in automatic waiting and its convenient debugging features (such as snapshots and automatic recording).
it('verifies login form', function() {
cy.visit('/login')
cy.get('input[name=username]').type('[email protected]')
cy.get('input[name=password]').type('password@123')
cy.contains('Log In').click()
// we should be redirected to /home
cy.url().should('include', '/home')
});
Let’s assume a user must log in to access the web application, which would require us to test the login process in every scenario. That is a lot of time spent re-testing something we’ve already tested.
To avoid duplication and reduce run-time, a better strategy would be to test the login functionality one time, and once we know this is working avoid logging in through the actual user interface. We can do this by stubbing out login requests or setting authentication manually before each test is run. This ensures we are confident the login process works through the UI, without the need to waste time and resources checking it every time.
E2E Tests Can Be a Maintenance Nightmare
A common struggle with E2E tests is the need to maintain them over time. As applications evolve we will see tests start to fail. This is less a criticism of E2E tests themselves, and more a criticism of how they are often written.
We previously covered solutions to simplify and minimize run-time. Thankfully most of those practices can also help minimize test maintenance. We also recommend avoiding certain practices.
- Avoid Brittle selectors: Leveraging
#id, or even better,data-attributeselectors instead of targeting elements based on HTML tags or CSS classes means that tests are less likely to break alongside application updates.
- Avoid “Implicit” Waits: It’s common during E2E testing for issues to arise because pages haven’t completed loading or views aren’t completely rendered. Testers often leverage implicit waits, which add a global “waiting” time when searching for elements if they are not found. The problem with this method is that it adds extensive run-time to tests AND frequently provides extremely vague errors. Explicit waits are a much better choice 99% of the time, especially when it comes to debugging failing tests. Even better, most automation frameworks have explicit waits built into their platform, making the use of them a no-brainer.
Check out this article from Selenium for a discussion on the difference between implicit and explicit waits.
- Don’t ignore failing tests: We know it’s tempting to set problematic tests to “skip” instead of figuring out the real issue. However, if we cannot trust the tests themselves, then they are providing very little value. In the end, you will prevent the possibility of missing bugs that could be encountered during actual application use.
- Avoid using the E2E method for everything: This is, unfortunately, a common problem. Once a shiny new E2E automation tool is discovered it’s natural to want to “automate everything”. However, this isn’t always wise or effective. Due to the nature of E2E tests and how slow and complex they can be to run, it’s usually best to focus on the “happy path” of your web application. Otherwise using an E2E test to examine edge cases can quickly cause your framework to grow into a large and unmaintainable mess. Keep it simple.
Ensuring the Longevity of your E2E Codebase
We touched above on what can cause E2E tests to become an unmanageable mess if not properly maintained. However, this doesn’t fix how we handle maintaining the codebase as the test suite grows along-side the application. Nor how to avoid the constant need to rewrite our test plans.
A simple solution to this problem involves planning ahead as we write our tests. Let’s look at a simple example of updating a user’s profile information on a form.
it('updates the users profile page', function() {
cy.visit('/update_profile')
cy.get('input[name=first_name]').type('Matt')
cy.get('input[name=last_name]').type('Smith')
cy.get('#user-state').select('KY')
cy.get('input[name=address]').type('123 Mission Lane')
cy.get('#phone-number').type('555-123-4567')
cy.get('#zip-code').type('12345')
cy.contains('Save').click()
// we should be redirected to /home and see a “success” message
cy.get('alert-success').should('contain', 'Profile Updated Successfully!')
cy.url().should('include', '/home')
});
This test looks simple and easy enough to change. But what if we had multiple tests that used this form and something as simple as an `id` change to the state dropdown causes all of them to break?
The time-consuming way would be to traverse through every single test that used that dropdown and update it to use the new ‘id’. That’s not a huge deal on a few scenarios, but imagine doing that across dozens of files and tests every time something was slightly adjusted. I’m sure we can agree that’s not a fun or efficient way to do things. The solution to this is using “abstraction” to our advantage in the form of “Page Objects”.
For more on page objects, read SeleniumHQ’s documents on Github.
Let’s take the previous example and make some modifications. I will abstract our test into a reusable component. I used a function in the example below, but using a class is another viable option. The goal here is we want to separate our logic away from the actual test.
user_profile = {
first_name: 'Matt',
last_name: 'Smith',
'state': 'KY',
'address': '123 Mission Lane',
'phone': '555-123-4567',
'zip': '12345'
}
const update_profile = (fixture) => {
const { first_name, last_name, state, address, phone, zip} = fixture
cy.get('input[name=first_name]').type(first_name)
cy.get('input[name=last_name]').type(last_name)
cy.get('#user-state').select(state)
cy.get('input[name=address]').type(address)
cy.get('#phone-number').type(phone)
cy.get('#zip-code').type(zip)
cy.contains('Save').click()
}
it('updates the users profile page', function() {
cy.visit('/update_profile')
update_profile(user_profile)
// we should be redirected to /home and see a “success” message
cy.get('alert-success').should('contain', 'Profile Updated Successfully!')
cy.url().should('include', '/home')
});
On first glance this looks like even more code, how does that help us? Well, the page object model does a few things for us:
- The tests themselves become more readable. You can see that the test itself was greatly shortened to only 4 lines as opposed to 10. It’s also much easier to quickly glance and see what this test is trying to accomplish.
- It’s much easier to make changes. Now we only need to make the change in one place, greatly reducing maintenance costs.
- It allows us to modify data easier. Before, we were hardcoding values into our tests themselves. Separating the logic away from our tests allows us to easily use custom data types/fixtures to pass into these page object methods.
TIP: An even better solution would be to separate our fixtures into sections so we can have one for every situation we may need.
Conclusion
E2E testing is an important and powerful part of any testing framework, and here we have highlighted some common problems encountered when integrating automation into a web application.
Fortunately, with proper techniques, we can reduce a lot of headaches that come along with writing these types of tests and make writing E2E tests useful, fun, and hopefully with fewer bugs!
— Keep on testing


